We are very grateful to Dr Doug Corrigan ("award winning global super-solver") for explaining the complexity of our genetic material - DNA in a way that most of us can understand. The following description appeared in a Tweet, and we felt it deserved a further, perhaps less transient platform.
 As someone once said, "the more we know, the more we know we don't know". With this in mind, it is perhaps useful to consider just how clumsy human attempts to interfere in the genetic process seem by comparison.
As someone once said, "the more we know, the more we know we don't know". With this in mind, it is perhaps useful to consider just how clumsy human attempts to interfere in the genetic process seem by comparison.
- Did you know that parts of your DNA machinery can rotate as fast as the turbine of a jet engine?
- Did you know that each cell with a nucleus contains a DNA strand six feet long?
- Did you know that we lose 50 billion cells every day?
- Did you know that 150 billion billion individual pieces of genetic material must be perfectly copied for each new cell?
We are also grateful to Nemo on Twitter for bringing the feature image to our attention.
Copying DNA
Every time one of our cells divides into two new cells, the entire genome must be copied. The human genome consists of 3 billion base pairs of information that make up the 6 feet of DNA in each cell. About 50 billion of our 30 trillion cells die every day, and must be replaced. For this to occur, 150 billion billion (150 followed by 12 zeros) pieces of genetic information (“bases”) must be perfectly copied.
The process of copying the DNA into a new strand is a highly orchestrated process that involves the cooperation of dozens of nano-molecular machines which all work in tandem to produce two double stranded molecules of DNA.
DNA consists of two linear strands that are helically wrapped around one another. To copy this DNA, it must first be unwound and the two strands must be separated. Then, protein enzymes read the code of the DNA, and synthesize an exact copy. Both strands of DNA are copied, producing two identical double-stranded molecules of DNA. The primary actor in the copying process is a molecular machine called DNA polymerase. After the DNA is unwound and separated, this enzyme attaches itself to one of the strands of the DNA and reads its code, base by base. As it reads the identity of each base, it recruits a complementary matching base and attaches it to the new strand, which is the copy.
Copying and correction systems enable replication fidelity
DNA polymerase scans the DNA and incorporates about 1,000 bases per second. DNA polymerase possesses an extraordinarily high copying fidelity, only making on average 1 error in every 10 million bases copied. DNA polymerases also have a proof-reading capability, which imparts them with the amazing ability to recognise when an error has been made, to:
- reverse direction,
- remove the base,
- incorporate the correct base, and then
- continue with copying the DNA at full speed.
In addition, there are other protein machines, known as post-replication mismatch repair enzymes, that monitor the DNA for uncaught errors. These enzymes correct the error by cutting the DNA at the site of the error, synthesizing a new strand with the correct sequence, and then gluing the new strand into the template. Together, these copying and correction systems enable replication fidelity of less than one mistake for every billion bases added.
Key molecules involved in DNA replication
There are many actors involved in the DNA replication process, but some of the major players are:
Topoisomerase - this machine begins to relax DNA from its supercoiled form.
DNA Helicase - This protein machine completely unwinds the two strands of DNA. It rotates as fast as the turbine of a jet engine.
DNA Gyrase - This protein helps to relieve the strain which is induced by unwinding the DNA strand.
Single Strand Binding Proteins - SSB proteins prevent the two strands of DNA from connecting back together after Helicase unwinds and separates them.
Primase - this enzyme helps to initiate DNA replication by providing a starting point for DNA polymerase.
DNA polymerase - there are multiple forms of DNA polymerase, but their collective function is to read the template strand of DNA, synthesize an exact complementary copy base by base, and to correct errors in real time.
DNA Clamp - this protein prevents DNA polymerase from disconnecting from the DNA as it copies the template strand.
Telomerase - Adds end-cap sequences to the ends of the DNA strand to maintain its length after copying.
The machines are making copies of their own blueprints, so that more machines can be built to copy more DNA blueprints
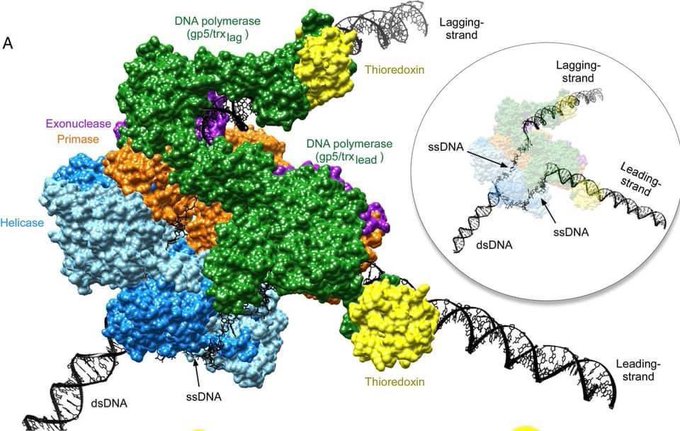 In the image, you can see a molecular model that shows some of these players and how they are attached to the DNA during replication. If that wasn’t already mind blowing enough, here’s the real kicker - The information to build every single one of these molecular machines is in the DNA that’s being copied by these machines. The machines are making copies of their own blueprints, so that more machines can be built to copy more DNA blueprints.
In the image, you can see a molecular model that shows some of these players and how they are attached to the DNA during replication. If that wasn’t already mind blowing enough, here’s the real kicker - The information to build every single one of these molecular machines is in the DNA that’s being copied by these machines. The machines are making copies of their own blueprints, so that more machines can be built to copy more DNA blueprints.
As Dr Corrigan says, "I don’t know of a more profound chicken or egg scenario than this one. This description of DNA replication is ridiculously simplified and wholly inadequate".


